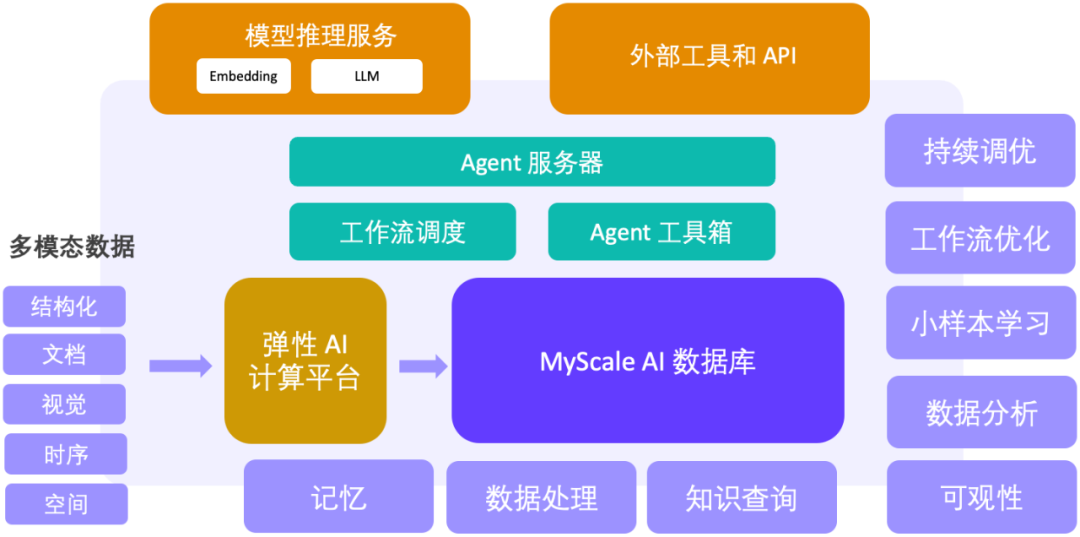
Transformer和TensorFlow是两个不同层面的概念,Transformer是一种深度学习模型架构,而TensorFlow是一个开源的机器学习框架,可以用来实现包括Transformer在内的各种深度学习模型。
Transformer
Transformer模型最初是在2017年的论文《Attention is All You Need》中提出的,它主要基于自注意力(Self-Attention)机制,并广泛应用于自然语言处理(NLP)领域,特别是在机器翻译任务中取得了显著的成果。Transformer模型的特点包括:
- 自注意力机制:能够同时考虑输入序列中的所有字(词),并自动找到序列内部的长距离依赖关系。
- 多头注意力:通过多次自注意力计算,可以让模型在不同的表示空间中学习到信息,增强了模型的表达能力。
- 位置编码:为了使模型能够理解词的顺序,Transformer引入了位置编码来表示词在序列中的位置。
- 编码器-解码器结构:Transformer模型通常采用编码器和解码器堆叠而成的结构,编码器用于处理输入序列,解码器用于生成输出序列。
TensorFlow
TensorFlow是一个由Google开发的开源机器学习框架,它提供了丰富的API来构建、训练和部署机器学习模型。TensorFlow支持多种类型的模型,包括深度神经网络、卷积神经网络(CNN)、循环神经网络(RNN)以及Transformer等。TensorFlow的主要特点包括:
- 灵活的架构:可以运行在多种硬件平台上,包括CPU、GPU和TPU。
- 丰富的API:包括低级API(如
tf.keras)和高级API(如TensorFlow Estimators),满足不同层次开发者的需求。 - 动态计算图:通过TensorFlow 2.x的Eager Execution,使得模型构建和调试更加直观和方便。
- 强大的社区支持:TensorFlow有着庞大的开发者社区,提供了大量的教程、工具和模型资源。
代码案例
以下是使用TensorFlow实现的简单Transformer模型的代码案例:
import tensorflow as tf
from tensorflow.keras.layers import Layer
# 自定义多头注意力层
class MultiHeadAttention(Layer):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
self.num_heads = num_heads
self.d_model = d_model
assert d_model % self.num_heads == 0
self.depth = d_model // self.num_heads
self.wq = tf.keras.layers.Dense(d_model)
self.wk = tf.keras.layers.Dense(d_model)
self.wv = tf.keras.layers.Dense(d_model)
self.dense = tf.keras.layers.Dense(d_model)
def split_heads(self, x, batch_size):
"""拆分最后一个维度到 (num_heads, depth).
转置结果使得形状为 (batch_size, num_heads, seq_len, depth)
"""
x = tf.reshape(x, (batch_size, -1, self.num_heads, self.depth))
return tf.transpose(x, perm=[0, 2, 1, 3])
def call(self, q, k, v, mask):
batch_size = tf.shape(q)[0]
q = self.wq(q)
k = self.wk(k)
v = self.wv(v)
q = self.split_heads(q, batch_size)
k = self.split_heads(k, batch_size)
v = self.split_heads(v, batch_size)
scaled_attention, attention_weights = self.scaled_dot_product_attention(q, k, v, mask)
scaled_attention = tf.transpose(scaled_attention, perm=[0, 2, 1, 3])
concat_attention = tf.reshape(scaled_attention, (batch_size, -1, self.d_model))
output = self.dense(concat_attention)
return output, attention_weights
def scaled_dot_product_attention(self, q, k, v, mask):
matmul_qk = tf.matmul(q, k, transpose_b=True)
dk = tf.cast(tf.shape(k)[-1], tf.float32)
scaled_attention_logits = matmul_qk / tf.math.sqrt(dk)
if mask is not None:
scaled_attention_logits += (mask * -1e9)
attention_weights = tf.nn.softmax(scaled_attention_logits, axis=-1)
output = tf.matmul(attention_weights, v)
return output, attention_weights
# 构建Transformer模型
def transformer(vocab_size, num_layers, dff, d_model, num_heads, dropout_rate, max_length, num_classes):
inputs = tf.keras.Input(shape=(max_length,))
padding_mask = tf.keras.Input(shape=(1, max_length, max_length))
embeddings = tf.keras.layers.Embedding(vocab_size, d_model)(inputs)
embeddings *= tf.math.sqrt(tf.cast(d_model, tf.float32))
embeddings = tf.keras.layers.Dropout(rate=dropout_rate)(embeddings)
for i in range(num_layers):
attn_output, _ = MultiHeadAttention(d_model, num_heads)(embeddings, embeddings, embeddings, padding_mask)
attn_output = tf.keras.layers.Dropout(rate=dropout_rate)(attn_output)
out1 = tf.keras.layers.LayerNormalization(epsilon=1e-6)(embeddings + attn_output)
ffn_output = tf.keras.layers.Dense(dff, activation='relu')(out1)
ffn_output = tf.keras.layers.Dense(d_model)(ffn_output)
ffn_output = tf.keras.layers.Dropout(rate=dropout_rate)(ffn_output)
embeddings = tf.keras.layers.LayerNormalization(epsilon=1e-6)(out1 + ffn_output)
logits = tf.keras.layers.Dense(num_classes)(embeddings)
model = tf.keras.Model(inputs=[inputs, padding_mask], outputs=logits)
return model
在上面的代码中,我们定义了一个Transformer模型,它包含多个注意力层和前馈网络层。这个模型可以用于序列到序列的任务,比如机器翻译或文本摘要。
vocab_size是输入词汇的大小。num_layers是注意力层和前馈网络层的数量。dff是前馈网络层的维度。d_model是注意力层的维度。num_heads是注意力头的数量。dropout_rate是 dropout 的概率,用于防止过拟合。max_length是输入序列的最大长度。num_classes是输出词汇的大小。
这个模型使用了MultiHeadAttention层,它在内部实现了多头自注意力机制。模型还包括了层归一化(LayerNormalization)和dropout层,这些都是Transformer模型的关键组件。
要使用这个模型,你需要定义输入数据和掩码,然后编译和训练模型。例如:
# 假设你的输入数据是整数序列,并且已经被预处理为适当的大小
input_data = tf.random.uniform((batch_size, max_length))
padding_mask = create_padding_mask(input_data)
# 创建Transformer模型
model = transformer(vocab_size=10000, num_layers=4, dff=512, d_model=128, num_heads=8, dropout_rate=0.1, max_length=max_length, num_classes=10000)
# 编译模型
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# 训练模型
history = model.fit([input_data, padding_mask], labels, batch_size=batch_size, epochs=num_epochs)
在上面的例子中,create_padding_mask 是一个函数,用于创建掩码,以屏蔽输入序列中的填充部分。labels 是你的目标数据,它们应该是独热编码的,以匹配输出的词汇大小。
在实际应用中,我们可能需要添加位置编码、更复杂的掩码处理、以及其他特定于任务的层和逻辑。此外,对于大型模型和数据集,需要使用更高级的训练技巧和优化器。